Best Youtube/Dailymotion Download & Convert to MP3


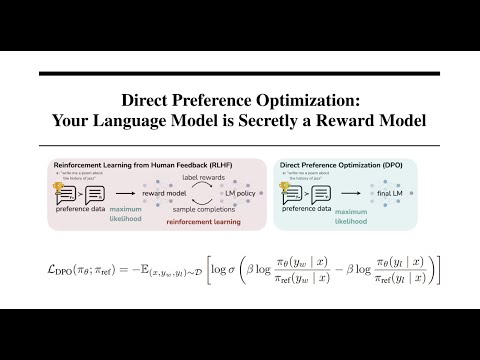
Direct Preference Optimization Your Language Model is Secretly a Reward Model DPO paper explained
Duration : 00:00:00 - Like :
Youtube : Download
Description :
...
Related Videos :
 |
Direct Preference Optimization: Your Language Model is Secretly a Reward Model | DPO paper explained By: AI Coffee Break with Letitia |
 |
Direct Preference Optimization (DPO) - How to fine-tune LLMs directly without reinforcement learning By: Serrano.Academy |
 |
Aligning LLMs with Direct Preference Optimization By: DeepLearningAI |
 |
Direct Preference Optimization (DPO) explained: Bradley-Terry model, log probabilities, math By: Umar Jamil |
 |
Direct Preference Optimization: Forget RLHF (PPO) By: Discover AI |
 |
Direct Preference Optimization (DPO): Your Language Model is Secretly a Reward Model Explained By: Gabriel Mongaras |
 |
Direct Preference Optimization (DPO) | Paper Explained By: Outlier |
|
